 .pdf
.pdf
Chapter 3 - Becnhmarking and Performance Measurement
1. Reframe Benchmarking
Reframe is a framework designed to abstract the complexities behind running regression tests on different high-performance computing (HPC) systems, hence facilitating the validation of software across varying systems. The framework aims to decouple runtime-specific behavior from the logic of individual tests, allowing for a single test to run seamlessly across different environments. Written in Python, it allows users to express their testing logic in Python, and utilizes decorators and hooks to provide extensibility and adaptability.
1.1. Utility
Reframe offers several advantages over shell scripts and other testing frameworks:
-
Portability: One of the primary reasons for using Reframe is its ability to run the same test across different HPC platforms without modification.
-
Flexibility: Users can write their own tests in Python, taking advantage of the expressiveness and extensibility of the language.
-
Extensibility: Through hooks and decorators, Reframe can be extended and adapted to support a wide range of testing scenarios.
-
Scalability: It supports running tests in parallel, making it efficient for large-scale testing scenarios.
-
Monitoring: With built-in performance tracking, Reframe makes it simple to monitor the performance of software components over time.
The given Python code is an example of how Reframe can be utilized to benchmark different random number generators using various compilation flags. The benchmarks are executed across five different C++ files representing different RNGs. Using parameterization, each RNG is compiled and run with various optimization flags. Post-execution, the runtime of each RNG with the respective flags is extracted and the best runtime for each RNG is reported. This systematic approach of using Reframe makes it easier to discern the performance implications of different compiler flags on RNGs, facilitating optimal compiler flag selection for desired performance.
flags = [
"-O1", "-O2", "-O3", "-Ofast",
"-O1 -march=native", "-O2 -march=native", "-O3 -march=native", "-Ofast -march=native",
"-O1 -march=native -funroll-loops", "-O2 -march=native -funroll-loops", "-O3 -march=native -funroll-loops", "-Ofast -march=native -funroll-loops",
"-O1 -march=native -fdisable-tree-cunrolli", "-O2 -march=native -fdisable-tree-cunrolli", "-O3 -march=native -fdisable-tree-cunrolli", "-Ofast -march=native -fdisable-tree-cunrolli"
]
cpp_files = [
'eigenrand_int.cpp',
'pcg_int.cpp',
'xoshiro_int.cpp',
'mersenne_twister_int.cpp',
'std_int.cpp'
]
@rfm.simple_test
class RNGBenchmarkTest(rfm.RegressionTest):
best_times = {}
valid_systems = ['*']
valid_prog_environs = ['gcc']
build_system = 'SingleSource'
sourcesdir = 'src/reframe'
flags = parameter(flags)
cpp_file = parameter(cpp_files)
def __init__(self, flags=None, cpp_file=None):
super().__init__()
# Default values for flags and cpp_file if not provided
self.flags = flags if flags else '-O3 -march=native'
self.cpp_file = cpp_file if cpp_file else 'std_int.cpp'
self.valid_systems = ['*']
self.valid_prog_environs = ['*']
self.build_system = 'SingleSource'
self.build_system.cxx = 'g++'
self.build_system.cxxflags = [self.flags]
self.sourcepath = self.cpp_file
# self.sanity_patterns = sn.assert_found(r'PASSED', self.stdout)
self.tags = {'production'}
@property
def name(self):
return f'{self.__class__.__name__}_flags_{self.flags.replace(" ", "_")}_{os.path.splitext(self.cpp_file)[0]}'
@run_before('run')
def set_prerun_cmds(self):
if self.cpp_file == 'eigenrand_int.cpp':
build_cmd = f'g++ -Wno-enum-compare {self.flags} -I{os.path.abspath("../extlibs/EigenRand")} -o {os.path.splitext(self.cpp_file)[0]} {self.cpp_file}'
self.prerun_cmds = [
f'echo "Building {self.cpp_file} with {self.flags}"',
'echo "Executing build command: ' + build_cmd + '"',
build_cmd,
f'./{os.path.splitext(self.cpp_file)[0]}'
]
if self.cpp_file == 'pcg_int.cpp':
build_cmd = f'g++ -Wno-enum-compare {self.flags} -I{os.path.abspath("../extlibs/pcg-cpp/include")} -o {os.path.splitext(self.cpp_file)[0]} {self.cpp_file}'
self.prerun_cmds = [
f'echo "Building {self.cpp_file} with {self.flags}"',
'echo "Executing build command: ' + build_cmd + '"',
build_cmd,
f'./{os.path.splitext(self.cpp_file)[0]}'
]
if self.cpp_file == 'xoshiro_int.cpp':
build_cmd = f'g++ -Wno-enum-compare {self.flags} -I{os.path.abspath("../extlibs/Xoshiro-cpp/include")} -o {os.path.splitext(self.cpp_file)[0]} {self.cpp_file}'
self.prerun_cmds = [
f'echo "Building {self.cpp_file} with {self.flags}"',
'echo "Executing build command: ' + build_cmd + '"',
build_cmd,
f'./{os.path.splitext(self.cpp_file)[0]}'
]
if self.cpp_file == 'mersenne_twister_int.cpp':
build_cmd = f'g++ -Wno-enum-compare {self.flags} -o {os.path.splitext(self.cpp_file)[0]} {self.cpp_file}'
self.prerun_cmds = [
f'echo "Building {self.cpp_file} with {self.flags}"',
'echo "Executing build command: ' + build_cmd + '"',
build_cmd,
f'./{os.path.splitext(self.cpp_file)[0]}'
]
if self.cpp_file == 'std_int.cpp':
build_cmd = f'g++ -Wno-enum-compare {self.flags} -o {os.path.splitext(self.cpp_file)[0]} {self.cpp_file}'
self.prerun_cmds = [
f'echo "Building {self.cpp_file} with {self.flags}"',
build_cmd,
f'./{os.path.splitext(self.cpp_file)[0]}'
]
@performance_function('μs')
def extract_runtime(self):
regex_map = {
'eigenrand_int.cpp': 'EigenRand,(\S+)',
'pcg_int.cpp': 'pcg-cpp,(\S+)',
'xoshiro_int.cpp': 'xoshiro-cpp,(\S+)',
'mersenne_twister_int.cpp': 'MersenneTwister,(\S+)',
'std_int.cpp': 'std::uniform_distribution,(\S+)'
}
perf = sn.extractsingle(regex_map[self.cpp_file], self.stdout, 1, float)
if self.cpp_file not in RNGBenchmarkTest.best_times or RNGBenchmarkTest.best_times[self.cpp_file][0] > perf:
RNGBenchmarkTest.best_times[self.cpp_file] = (perf, self.flags) # update if this time is the best
return perf
@sanity_function
def assert_output(self):
regex_map = {
'eigenrand_int.cpp': 'EigenRand,(\S+)',
'pcg_int.cpp': 'pcg-cpp,(\S+)',
'xoshiro_int.cpp': 'xoshiro-cpp,(\S+)',
'mersenne_twister_int.cpp': 'MersenneTwister,(\S+)',
'std_int.cpp': 'std::uniform_distribution,(\S+)'
}
return sn.assert_found(regex_map[self.cpp_file], self.stdout)2. Random Number Generators
When dealing with solar shading masks computation, it’s strongly recommended to use the Monte-Carlo technic, namely during the ray-tracing part of the algorithm enabling one to backtrace the paths to find shaded locations due to the environment. But this comes at a cost, since it’s mathematically accurate only when tracing multiple rays in random directions, being the foundation of this method.
Since this project is at district or even city scale, the use of a fast Random Number Generators (RNG) is necessary. Despite numerous benchmarks already been done, we decided to compare some of the fastest open-source libraries, all heavily relying on Vectorization, multi-threading or multicore processing, and performance-targeted compiling flags (such as -03 to -0fast). Since Intel processors have specific instructions and extensions (such as Streaming SIMD Extensions, SSE2) and Advanced Vector Extensions (AVX), the MKL advanced Mathematics library naturally benefits of efficient vectorized operations.
2.1. RNG Speed Benchmark
2.1.1. Explicit In-App Benchmarking
We have to adopt rigorous coding methods, proving and explaining our reasoning behind every choice made during the internship. In order to settle on a specific method, benchmarks have to be performed. Since many different random number generators have to be tested, a first automation of the benchmarking process was done using a bash script, which can be found in the benchmarking folder of the repository. This script compiles and executes the code for each RNG, and outputs the results in a .csv file as well as in the terminal, in the form of a table, stating the best execution times for each method, and the flags used during compilation.
set -e
flags=(
"-Ofast"
"-O3"
"-O2"
"-Ofast -funroll-loops"
"-O3 -funroll-loops"
"-O2 -funroll-loops"
"-Ofast -funroll-loops -funsafe-math-optimizations"
"-Ofast -march=znver2"
"-Ofast -ftlo"
)
# Obtain the path to the script
SCRIPT_PATH="$(dirname "$(realpath "$0")")"
# Obtain the root directory path by removing /src from the script path
ROOT_PATH="${SCRIPT_PATH%/src}"
cd "$ROOT_PATH/build/default/src"
echo "Select the config file: "
echo "1. exampleShadingMask"
echo "2. 19buildingsStrasbourg"
read -p "Enter the number (1 or 2): " NUMBER1
case "$NUMBER1" in
1)
CONFIG_FILE="$ROOT_PATH/src/cases/exampleShadingMask/exampleShadingMask.cfg"
;;
2)
CONFIG_FILE="$ROOT_PATH/src/cases/19buildingsStrasbourg/19buildingsStrasbourg.cfg"
;;
*)
echo "Invalid input! Enter 1 or 2."
exit 1
esac
declare -A best_times_map
declare -A best_flags_map
for method in "RNG STD" "RNG XOSHIRO" "RNG PCG" "RNG MIX" "RNG EIGEN" "RNG EIGEN CAST" "RNG EIGEN VEC"; do
best_times_map["$method"]=1000
best_flags_map["$method"]=""
done
for ((NUMBER=1; NUMBER<${#flags[@]}+1; NUMBER++))
do
EXECUTABLE="./example_ShadingMasks_comparison${NUMBER}"
echo "Running the command : $EXECUTABLE --config-file $CONFIG_FILE"
output=$( $EXECUTABLE --config-file $CONFIG_FILE )
for method in "${!best_times_map[@]}"; do
execution_time=$(echo "$output" | grep -oP "(?<=Elapsed time for shading mask computation with $method:)[0-9.]+")
if (( $(echo "$execution_time < ${best_times_map[$method]}" | bc -l) ))
then
best_times_map["$method"]=$execution_time
best_flags_map["$method"]=${flags[$NUMBER]}
fi
done
done
# Display the summary
printf "\n\n"
printf "==============================================================================\n"
printf "%-25s %-10s %s\n" "METHOD" "TIME (seconds)" "FLAGS"
printf "==============================================================================\n"
for method in "${!best_times_map[@]}"; do
printf "%-25s %-15s %s\n" "$method:" "${best_times_map[$method]} s" "'${best_flags_map[$method]}'"
done
printf "==============================================================================\n"This is one of its outputs, showing an improvement of 8.63% in execution time when using the -Ofast -funroll-loop flags on the Xoshiro method:
==============================================================================
METHOD TIME (seconds) FLAGS
==============================================================================
RNG STD: 9.389095158 s '-O2'
RNG EIGEN: 9.121100925 s '-O2'
RNG EIGEN CAST: 9.19422145 s '-O2 -funroll-loops'
RNG PCG: 9.382495989 s '-Ofast -funroll-loops'
RNG XOSHIRO: 8.578198413 s '-Ofast -funroll-loops'
RNG EIGEN VEC: 9.554856035 s '-Ofast -funroll-loops'
RNG MIX: 9.412993456 s '-O2'
==============================================================================But such performance improvements are inconsistent, even for a single method and flag since some RNGs, or the tasks using them (like the state-based traversal algorithm), might have non-deterministic paths. This means that even with the same seed, the exact sequence of operations might differ slightly in different runs, leading to performance variations.
These benchmarks can be launched after launching these commands from the root of the repo:
cmake --preset default
cmake --build build/default
./src/run_all.shIf one intents to benchmark all methods on a specific set of flags, the run_examples.sh script can be used as follows:
cmake --preset default
cmake --build build/default
./src/run_examples.shAnd choosing the flags and test cases using the terminal.
2.1.2. Available Methods
As said, numerous methods are open-source and available to use, built upon different fundamentals. The Xoshiro-Cpp is a lightweight, high-performance random number generator known for its speed and low memory consumption. The Mersenne Twister, on the other hand, is widely used for its long period and good statistical properties. std::random provides a standardized interface for random number generation in C++, offering various generators including Mersenne Twister. Eigen::Rand is a random number generator headers library strongly relying on Eigen’s vectorization capabilities, useful for generating random matrices in numerical computations. Intel MKL offers high-performance, vectorized random number generation routines optimized for scientific and numerical computing while pcg-cpp is a Permuted Congruential Generator implementation balancing speed and randomness for simulations and gaming.
The tested libraries are: - EigenRand: a random number generator headers library strongly relying on Eigen’s vectorization capabilities, useful for generating random matrices in numerical computations (especially random vectors in our case). - EigenRand’s real generator casted to int: the same as above, but casting the generated real numbers to integers in order to gain speed. - PCG-CPP: a Permuted Congruential Generator implementation balancing speed and randomness for simulations. - Xoshiro-Cpp: a lightweight, high-performance random number generator reknown for its speed and low memory consumption. - Mersenne Twister: a widely used random number generator for its long period and good statistical properties, available in the standard library. - Intel MKL: a high-performance, vectorized random number generation routines optimized for scientific and numerical computing. - std::random: a standardized interface for random number generation in C++, offering various generators including Mersenne Twister.
Below you can see a first execution time comparison, using the std::chrono library to measure the time taken by each method to generate 1000000 random numbers. The code was compiled using different usual flags, such as -O3, -Ofast, -O2 and -O1.
![Barplot comparing execution time][600](../../_images/flagcomparison.png)
We can observe that all of the presented methods, except for Eigen’s one, are outperforming the standard library.
2.1.3. Different Flags
Since Intel’s oneAPI MKL library is by far the highest speed RNG, we benchmarked it using more specific flags, such as march=native in order to enable all the processor’s extensions, and switching between sequential and threaded modes. The results are shown below:
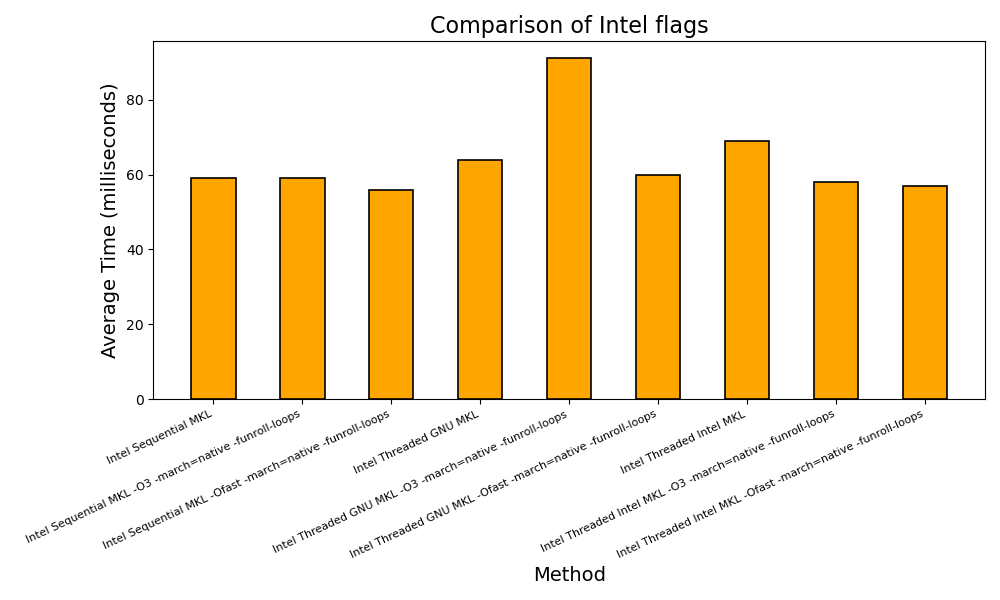
And below the second speed test done on Gaia, a system composeed of 192 AMD EPYC 7552 48-Core Processors. During this second benchmark, we cycled through most of the different compilation flags combinations, and the results are shown below:
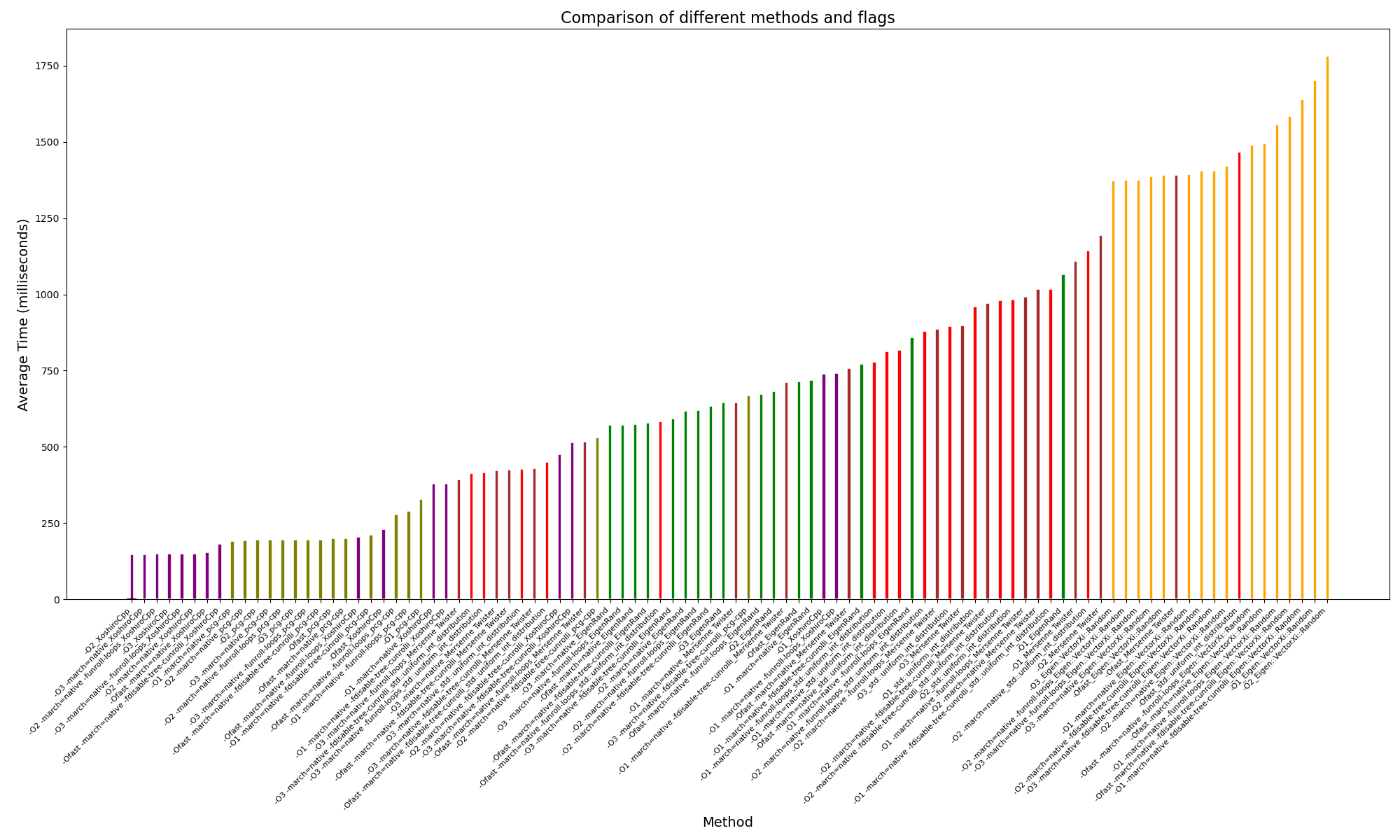
Here is a website describing the use-cases of each compilation flag and what they do.
The -Ofast and -O3 flags enable the following optimizations for the user:
-
Loop unrolling: This optimization involves repeating the body of a loop multiple times, which reduces loop overhead and enables better parallelism.
-
Code redundancy elimination: The compiler detects portions of code that are needlessly repeated and replaces them with reused references, reducing the amount of executed code.
-
Vectorization: Loops are transformed to use SIMD (Single Instruction, Multiple Data) instructions to perform simultaneous operations on multiple data elements. This effectively exploits the parallel computing capabilities of modern processors.
-
Loop fusion: Independent loops are merged into a single loop, reducing overhead and improving performance by reducing the number of iterations.
-
Function inlining: Function calls are replaced with the body of the function itself, avoiding the overhead of function calls. Unused variable elimination: Variables that are not used in the code are detected and removed, reducing memory consumption.
-
Arithmetic operation optimization: The compiler can perform mathematical transformations to simplify expressions and reduce the number of necessary operations.
2.2. RNG Quality Benchmark and influence on the Monte Carlo Integration
Monte Carlo integration, when applied to the computation of solar shading masks, leverages random sampling to model intricate interactions of light—its scattering, reflection, and absorption across various surfaces. The random number generator (RNG) underpinning this process is of paramount importance.
Firstly, the convergence rate and accuracy of a Monte Carlo method are intimately tied to the quality of its random samples. An RNG of superior quality will ensure a sequence that’s uniformly distributed across the integration domain, which in turn guarantees swifter and more precise estimates. On the flip side, an RNG that’s lacking might inadvertently inject patterns or biases into the sequence. Such biases can warp the computed shading masks, veering the results away from realism and accuracy. In fact, we can observe how the estimation of the error in the Monte Carlo method is directly proportional to the variance of the random variable (some information found on Wikipedia and combined with this course):
where f is the function being integrated, x_i is the random sample, N is the number of samples, and mu is the mean of the function. But since:
where I is the integral, Q_N is the Monte Carlo estimation, and p(x_i) is the probability density function of the random variable x_i, we can deduce that:
We observe that the variance does not need any normalization, as the chosen probability density function p(x_i) is uniform. Finally, if the sequence \(\sigma^2_i\) is bounded, the variance decreases asymptomatically as the number of samples increases:
Moreover, the variance of the Monte Carlo estimation, which dictates the required sample size for a particular accuracy level, is also influenced by the RNG. An RNG that fosters uniform distribution curtails variance and amplifies the method’s efficiency. Yet, this isn’t just about uniformity. It’s crucial that the random numbers be independent of one another. Any correlation between the numbers can introduce errors, and in the realm of light transport simulations, correlated random paths might birth noticeable artifacts in the output.
Reproducibility is another facet where the RNG shines. There might be instances where the exact replication of a prior Monte Carlo outcome is desired. In such cases, the ability to seed an RNG ensures that we can reproduce the same sequence of numbers, and consequently, the same results. Furthermore, as solar shading computations often dive into the realm of vast numbers—potentially billions of samples in complex settings—an RNG of merit must be adept at churning out a vast array without falling into repetitive loops or discernible patterns.
Lastly, in an age where parallel processing is commonplace, it’s indispensable for the RNG to be parallel-friendly. As multiple threads work in tandem, the RNG should be competent enough to offer each thread its unique, non-overlapping sequence, ensuring consistency and preventing any cross-correlation.
Each random number generator’s quality can be benchmarked using their repositories, also working with the submodules available in the feelpp/solar-shading repository.