 .pdf
.pdf
GPGPU (General-Purpose Graphics Processing Unit)

1. Definition
A General-Purpose Graphics Processing Unit (GPGPU) is a graphics processing unit (GPU) that is programmed for purposes beyond graphics processing, such as performing computations typically conducted by a Central Processing Unit (CPU).
GPGPU is short for general-purpose computing on graphics processing units. Graphics processors or GPUs today are capable of much more than calculating pixels in video games. For this, Nvidia has been developing for four years a hardware interface and a programming language derived from C, CUDA ( C*ompute *Unified Device Architecture ).
This technology, known as GPGPU ( General - P*urpose computation on *G*raphic *P*rocessing *Units ) exploits the computing power of GPUs for the processing of massively parallel tasks. Unlike the CPU, a GPU is not suited for fast processing of tasks that run sequentially. On the other hand, it is very suitable for processing parallelizable algorithms.
-
Array of independent "cores" called calculation units
-
High bandwidth, banked L2 caches and main memory
-
Banks allow several parallel accesses
-
100s of GB/s
-
-
Memory and caches are generally inconsistent
Compute units are based on SIMD hardware
-
Both AMD and NVIDIA have 16-element wide SIMDs
-
Large registry files are used for fast context switching
-
-
No save/restore state
-
Data is persistent throughout the execution of the thread
-
Both providers have a combination of automatic L1 cache and user-managed scratchpad
-
Scratchpad is heavily loaded and has very high bandwidth (~terabytes/second)
-
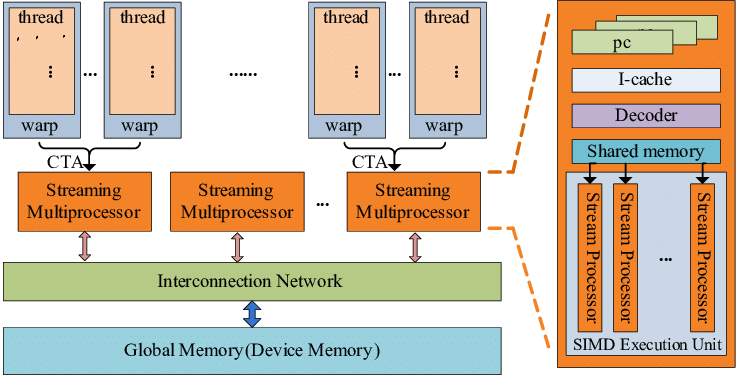
Work items are automatically grouped into hardware threads called "wavefronts" (AMD) or "warps" (NVIDIA)
− Single instruction stream executed on SIMD hardware − 64 work items in a wavefront, 32 in a string
-
The instruction is issued multiple times on the 16-channel SIMD unit
-
Control flow is managed by masking the SIMD channel
NVIDIA coined "Single Instruction Multiple Threads" (SIMT) to refer to multiple (software) threads sharing a stream of instructions
-
Work items run in sequence on SIMD hardware
-
Multiple software threads are executed on a single hardware thread
-
Divergence between managed threads using predication
-
-
Accuracy is transparent to the OpenCL model
-
Performance is highly dependent on understanding work items to SIMD mapping
2. Architecture of a GPU versus CPU
Such an architecture is said to be "throughput-oriented". The latest from the Santa-Clara firm, codenamed “Fermi” has 512 cores.
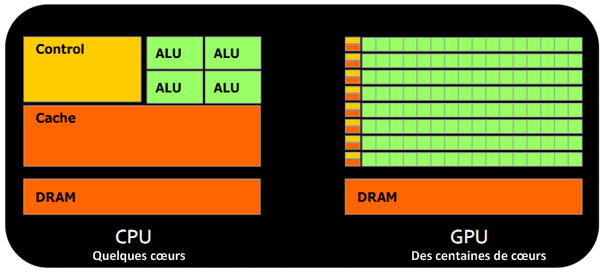
Traditional microprocessors (CPUs) are essentially "low latency oriented". The goal is to minimize the execution time of a single sequence of a program by reducing latency as much as possible. This design takes the traditional assumption that parallelism in the operations that the processor must perform is very rare. Throughput-oriented processors assume that their workload requires significant parallelism. The idea is not to execute the operations as quickly as possible sequentially, but to execute billions of operations simultaneously in a given time, the execution time of one of these operations is ultimately almost irrelevant. In a video game, for example, performance is measured in FPS (Frames Per Seconds). To do this, an image, with all the pixels, must be displayed every 30 milliseconds (approximately). It doesn’t matter how long a single pixel is displayed. This type of processor has small independent calculation units which execute the instructions in the order in which they appear in the program, there is ultimately little dynamic control over the execution. Thea term SIMD is used for these processors (Single Instruction Multiple Data). Each PU (Processing Unit) does not necessarily correspond to a processor, they are calculation units. In this mode, the same instruction is applied simultaneously to several data. Less control logic means more space on the chip dedicated to the calculation. However, this also comes at a cost. A SIMD execution gets a performance peak when parallel tasks follow the same branch of execution, which deteriorates when the tasks branch off. Indeed, the calculation units assigned to a branch will have to wait for the execution of the calculation units of the previous branch. This results in hardware underutilization and increased execution time. The efficiency of the SIMD architecture depends on the uniformity of the workload. However, due to the large number of computational units, it may not be very important to have some threads blocked if others can continue their execution. Long-latency operations performed on one thread are "hidden" by others ready to execute another set of instructions. For a quad or octo-core CPU, the creation of threads and their scheduling has a cost. For a GPU, the relative latency "covers" these 2 steps, making them negligible. However, memory transfers have greater implications for a GPU than a CPU because of the need to move data between CPU memory and GPU memory.
3. GPU versus GPGPU
Essentially all modern GPUs are GPGPUs. A GPU is a programmable processor on which thousands of processing cores run simultaneously in massive parallelism, where each core is focused on making efficient calculations, facilitating real-time processing and analysis of enormous datasets. While GPUs were originally designed primarily for the purpose of rendering images, GPGPUs can now be programmed to direct that processing power toward addressing scientific computing needs as well.
If a graphics card is compatible with any particular framework that provides access to general purpose computation, it is a GPGPU. The primary difference is that where GPU computing is a hardware component, GPGPU is fundamentally a software concept in which specialized programming and equipment designs facilitate massive parallel processing of non-specialized calculations.
4. What is GPGPU Acceleration ?
GPGPU acceleration refers to a method of accelerated computing in which compute-intensive portions of an application are assigned to the GPU and general-purpose computing is relegated to the CPU, providing a supercomputing level of parallelism. While highly complex calculations are computed in the GPU, sequential calculations can be performed in parallel in the CPU.
5. How to Use GPGPU ?
Writing GPU enabled applications requires a parallel computing platform and application programming interface (API) that allows software developers and software engineers to build algorithms to modify their application and map compute-intensive kernels to the GPU. GPGPU supports several types of memory in a memory hierarchy for designers to optimize their programs. GPGPU memory is used for transferring data between device and host — shared memory is an efficient way for threads in the same block to share their runtime and data. A GPU Database uses GPU computation power to analyze massive amounts of information and return results in milliseconds.
GPGPU-Sim, developed at the University of British Columbia, provides a detailed simulation model of a contemporary GPU running CUDA and/or OpenCL workloads. Some open-source GPGPU benchmarks containing CUDA codes include: Rodinia benchmarks, SHOC, Tensor module in Eigen 3.0 open-source C++ template library for linear algebra, and SAXPY benchmark. Metal GPGPU, an Apple Inc. API, is a low-level graphics programming API for iOS and macOS but it can also be used for general-purpose compute on these devices.
6. GPGPU in CUDA
The CUDA platform is a software layer that gives direct access to the GPU’s virtual instruction set and parallel computational elements for the execution of compute kernels. Designed to work with programming languages such as C, C++, and Fortran, CUDA is an accessible platform, requiring no advanced skills in graphics programming, and available to software developers through CUDA-accelerated libraries and compiler directives. CUDA-capable devices are typically connected with a host CPU and the host CPUs are used for data transmission and kernel invocation for CUDA devices.
The CUDA model for GPGPU accelerates a wide variety of applications, including GPGPU AI, computational science, image processing, numerical analytics, and deep learning. The CUDA Toolkit includes GPU-accelerated libraries, a compiler, programming guides, API references, and the CUDA runtime.