 .pdf
.pdf
GPU (Graphics Processing Unit is a graphics (co-)processor)

1. Definition
Graphics Processing Unit is a graphics (co-)processor capable of very efficiently performing calculations on images (2D, 3D, videos, etc.). The raw computing power offered is higher due to the large number of processors present on these cards. This is why it is not uncommon to obtain large acceleration factors between CPU and GPU for the same application.
Explicit code targeting GPUs: CUDA, HIP, SYCL, Kokkos, RAJA,…
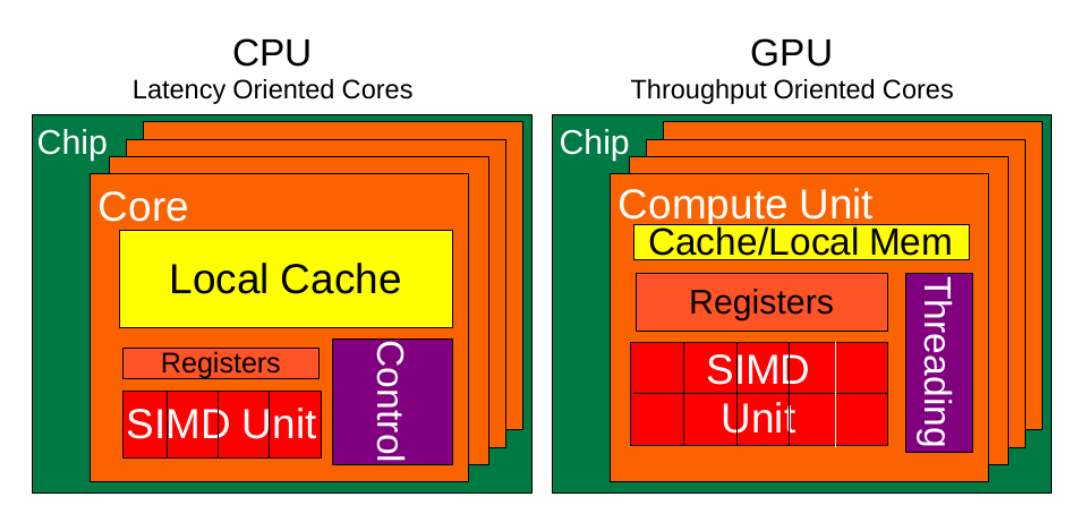
Fig: illustrates the main hardware architecture differences between CPUs and GPUs. The transistor counts associated with various functions are represented abstractly by the relative sizes of the various shaded areas. In the figure, the green corresponds to the calculation; gold is instruction processing; purple is the L1 cache; blue is top level cache and orange is memory (DRAM, which really should be thousands of times larger than caches).
GPUs were originally designed to render graphics. They work great for shading, texturing, and rendering the thousands of independent polygons that make up a 3D object. CPUs, on the other hand, are meant to control the logical flow of any general-purpose program, where a lot of digit manipulation may (or may not) be involved. Due to these very different roles, GPUs are characterized by having many more processing units and higher overall memory bandwidth, while CPUs offer more sophisticated instruction processing and faster clock speed.
2. CPU vs GPU comparison
| CPU: Latency-oriented design | GPU: Throughput Oriented Design | |
|---|---|---|
Clock |
High clock frequency |
Moderate clock frequency |
Caches |
Large sizes Converts high latency accesses in memory to low latency accesses in cache |
Small caches To maximize memory throughput |
Control |
Sophisticated control system Branch prediction to reduce latency due to branching |
Single controlled No branch prediction No data loading |
Powerful Arithmetic Logic Unit (ALU) |
Reduced operation latency |
Numerous, high latency but heavily pipelined for high throughput |
Other aspects |
Lots of space devoted to caching and control logic. Multi-level caches used to avoid latency Limited number of registers due to fewer active threads Control logic to reorganize execution, provide ILP, and minimize pipeline hangs |
Requires a very large number of threads for latency to be tolerable |
Beneficial aspects for applications |
CPUs for sequential games where latency is critical. CPUs can be 10+X faster than GPUs for sequential code. |
GPUs for parallel parts where throughput is critical. GPUs can be 10+X faster than GPUs for parallel code. |