 .pdf
.pdf
Heat Equation Parallel Programming Comparison
1. Heat equation in 2D
1.1. Theory
Heat (or diffusion) equation is a partial differential equation that describes the variation of temperature in a given region over time
\begin{align*} \frac{\partial u}{\partial t} = \alpha \nabla^2 u \end{align*}
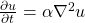
where u(x, y, t) is the temperature field that varies in space and time, and α is the thermal diffusivity constant.
We limit ourselvels to two dimensions (a plane) where Laplacian can be discretized in a grid with finite differences as
\begin{align*} \nabla^2 u &= \frac{u(i-1,j)-2u(i,j)u(i+1,j)}{(\Delta x)^2} \\ & \frac{u(i,j-1)-2u(i,j)+u(i,j+1)}{(\Delta y)^2} \end{align*}
where ∆x and ∆y are the grid spacing of the temperature grid u.
Given an initial condition (u(t=0) = u0) one can follow the time dependence of the temperature field with explicit time evolution method:
\begin{align*} u^{m+1}(i,j) = u^m(i,j) + \Delta t \alpha \nabla^2 u^m(i,j) \end{align*}
Note: The algorithm is stable only when
2. Code
The solver carries out the time development of the 2D heat equation over the number of time steps provided by the user. The default geometry is a flat rectangle (with grid size provided by the user), but other shapes may be used via input files. The program will produce an image (PNG) of the temperature field after every 100 iterations.
/* Heat equation solver in 2D. */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include <mpi.h>
#include "heat.h"
int main(int argc, char **argv)
{
double a = 0.5; //!< Diffusion constant
field current, previous; //!< Current and previous temperature fields
double dt; //!< Time step
int nsteps; //!< Number of time steps
int image_interval = 1500; //!< Image output interval
parallel_data parallelization; //!< Parallelization info
double dx2, dy2; //!< Delta x and y squared
double average_temp; //!< Average temperature
double start_clock, stop_clock; //!< Time stamps
MPI_Init(&argc, &argv);
initialize(argc, argv, ¤t, &previous, &nsteps, ¶llelization);
/* Output the initial field */
write_field(¤t, 0, ¶llelization);
average_temp = average(¤t);
if (parallelization.rank == 0) {
printf("Average temperature at start: %f\n", average_temp);
}
/* Largest stable time step */
dx2 = current.dx * current.dx;
dy2 = current.dy * current.dy;
dt = dx2 * dy2 / (2.0 * a * (dx2 + dy2));
/* Get the start time stamp */
start_clock = MPI_Wtime();
/* Time evolve */
for (int iter = 1; iter <= nsteps; iter++) {
exchange(&previous, ¶llelization);
evolve(¤t, &previous, a, dt);
if (iter % image_interval == 0) {
write_field(¤t, iter, ¶llelization);
}
/* Swap current field so that it will be used
as previous for next iteration step */
swap_fields(¤t, &previous);
}
stop_clock = MPI_Wtime();
/* Average temperature for reference */
average_temp = average(&previous);
/* Determine the CPU time used for the iteration */
if (parallelization.rank == 0) {
printf("Iteration took %.3f seconds.\n", (stop_clock - start_clock));
printf("Average temperature: %f\n", average_temp);
if (argc == 1) {
printf("Reference value with default arguments: 59.281239\n");
}
}
/* Output the final field */
write_field(&previous, nsteps, ¶llelization);
finalize(¤t, &previous);
MPI_Finalize();
return 0;
}/* Heat equation solver in 2D. */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include <mpi.h>
#ifdef _OPENMP
#include <omp.h>
#endif
#include "heat.h"
int main(int argc, char **argv)
{
double a = 0.5; //!< Diffusion constant
field current, previous; //!< Current and previous temperature fields
double dt; //!< Time step
int nsteps; //!< Number of time steps
int image_interval = 1500; //!< Image output interval
parallel_data parallelization; //!< Parallelization info
double dx2, dy2; //!< Delta x and y squared
double average_temp; //!< Average temperature
double start_clock, stop_clock; //!< Time stamps
int provided; // thread-support level
MPI_Init_thread(&argc, &argv, MPI_THREAD_MULTIPLE, &provided);
if (provided < MPI_THREAD_MULTIPLE) {
printf("MPI_THREAD_MULTIPLE thread support level required\n");
MPI_Abort(MPI_COMM_WORLD, 5);
}
#pragma omp parallel
{
initialize(argc, argv, ¤t, &previous, &nsteps, ¶llelization);
/* Output the initial field */
#pragma omp single
{
write_field(¤t, 0, ¶llelization);
average_temp = average(¤t);
if (parallelization.rank == 0) {
printf("Average temperature at start: %f\n", average_temp);
}
/* Largest stable time step */
dx2 = current.dx * current.dx;
dy2 = current.dy * current.dy;
dt = dx2 * dy2 / (2.0 * a * (dx2 + dy2));
} // end omp simple
/* Get the start time stamp */
start_clock = MPI_Wtime();
/* Time evolve */
for (int iter = 1; iter <= nsteps; iter++) {
#pragma omp single
exchange(&previous, ¶llelization);
evolve(¤t, &previous, a, dt);
if (iter % image_interval == 0) {
#pragma omp single
write_field(¤t, iter, ¶llelization);
}
/* Swap current field so that it will be used
as previous for next iteration step */
#pragma omp single
swap_fields(¤t, &previous);
}
} // end omp parallel
stop_clock = MPI_Wtime();
/* Average temperature for reference */
average_temp = average(&previous);
/* Determine the CPU time used for the iteration */
if (parallelization.rank == 0) {
printf("Iteration took %.3f seconds.\n", (stop_clock - start_clock));
printf("Average temperature: %f\n", average_temp);
if (argc == 1) {
printf("Reference value with default arguments: 59.281239\n");
}
}
/* Output the final field */
write_field(&previous, nsteps, ¶llelization);
finalize(¤t, &previous);
MPI_Finalize();
return 0;
}/* Main solver routines for heat equation solver */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
#include <mpi.h>
#include <cuda_runtime_api.h>
#include "heat.h"
/* Update the temperature values using five-point stencil */
__global__ void evolve_kernel(double *currdata, double *prevdata, double a, double dt, int nx, int ny,
double dx2, double dy2)
{
/* Determine the temperature field at next time step
* As we have fixed boundary conditions, the outermost gridpoints
* are not updated. */
int ind, ip, im, jp, jm;
// CUDA threads are arranged in column major order; thus j index from x, i from y
int j = blockIdx.x * blockDim.x + threadIdx.x;
int i = blockIdx.y * blockDim.y + threadIdx.y;
if (i > 0 && j > 0 && i < nx+1 && j < ny+1) {
ind = i * (ny + 2) + j;
ip = (i + 1) * (ny + 2) + j;
im = (i - 1) * (ny + 2) + j;
jp = i * (ny + 2) + j + 1;
jm = i * (ny + 2) + j - 1;
currdata[ind] = prevdata[ind] + a * dt *
((prevdata[ip] -2.0 * prevdata[ind] + prevdata[im]) / dx2 +
(prevdata[jp] - 2.0 * prevdata[ind] + prevdata[jm]) / dy2);
}
}
void evolve(field *curr, field *prev, double a, double dt)
{
int nx, ny;
double dx2, dy2;
nx = prev->nx;
ny = prev->ny;
dx2 = prev->dx * prev->dx;
dy2 = prev->dy * prev->dy;
/* CUDA thread settings */
const int blocksize = 16; //!< CUDA thread block dimension
dim3 dimBlock(blocksize, blocksize);
// CUDA threads are arranged in column major order; thus make ny x nx grid
dim3 dimGrid((ny + 2 + blocksize - 1) / blocksize,
(nx + 2 + blocksize - 1) / blocksize);
evolve_kernel<<<dimGrid, dimBlock>>>(curr->devdata, prev->devdata, a, dt, nx, ny, dx2, dy2);
cudaDeviceSynchronize();
}
void enter_data(field *temperature1, field *temperature2)
{
size_t datasize;
datasize = (temperature1->nx + 2) * (temperature1->ny + 2) * sizeof(double);
cudaMalloc(&temperature1->devdata, datasize);
cudaMalloc(&temperature2->devdata, datasize);
cudaMemcpy(temperature1->devdata, temperature1->data, datasize, cudaMemcpyHostToDevice);
cudaMemcpy(temperature2->devdata, temperature2->data, datasize, cudaMemcpyHostToDevice);
}
/* Copy a temperature field from the device to the host */
void update_host(field *temperature)
{
size_t datasize;
datasize = (temperature->nx + 2) * (temperature->ny + 2) * sizeof(double);
cudaMemcpy(temperature->data, temperature->devdata, datasize, cudaMemcpyDeviceToHost);
}
/* Copy a temperature field from the host to the device */
void update_device(field *temperature)
{
size_t datasize;
datasize = (temperature->nx + 2) * (temperature->ny + 2) * sizeof(double);
cudaMemcpy(temperature->devdata, temperature->data, datasize, cudaMemcpyHostToDevice);
}…