 .pdf
.pdf
Complexity and Performance
To assess the complexity and performance of our program, we executed it on the High-Performance Computing (HPC) cluster Gaya. This cluster consists of a DELL PowerEdge R7525 head node and six DELL PowerEdge R6525 compute nodes, providing a total of 768 multi-threaded cores on the compute nodes and 96 cores on the head node. Gaya offers 150 TB of storage for data and an extremely fast 15 TB NVME scratch space. The head node is equipped with two AMD EPYC 7552 48-Core Processors running at 2.2GHz, totaling 192 virtual cores, and 1024 GB of RAM. Each compute node features two AMD EPYC 7713 64-Core Processors running at 2GHz, totaling 256 virtual cores, and 512 GB of RAM. The nodes are interconnected via Broadcom Adv. Dual 10GBASE-T Ethernet and Mellanox ConnectX-6 Dx Dual Port 100 GbE for MPI communication. For our benchmarks, we used a single exclusive node with 256 cores and 512 GB of RAM.
We used four different bounding boxes of Strasbourg city center as our test area, all centered at the same point but with varying sizes:
|
|
|
|
1. LOD and number of faces
Because the number of faces significantly impacts the performance of our program, we analyzed the faces generated for each bounding box. The following figures illustrate the relationship between the number of trees and the number of faces produced by our program at each LOD level.
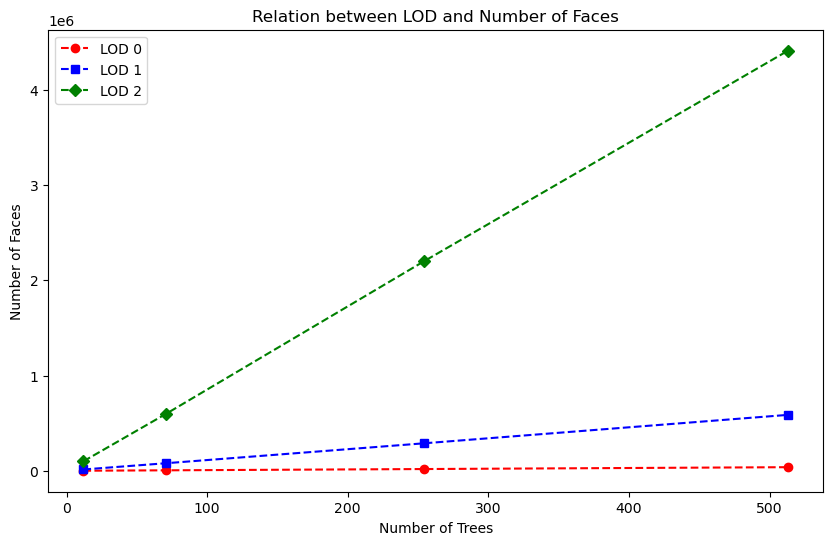
|
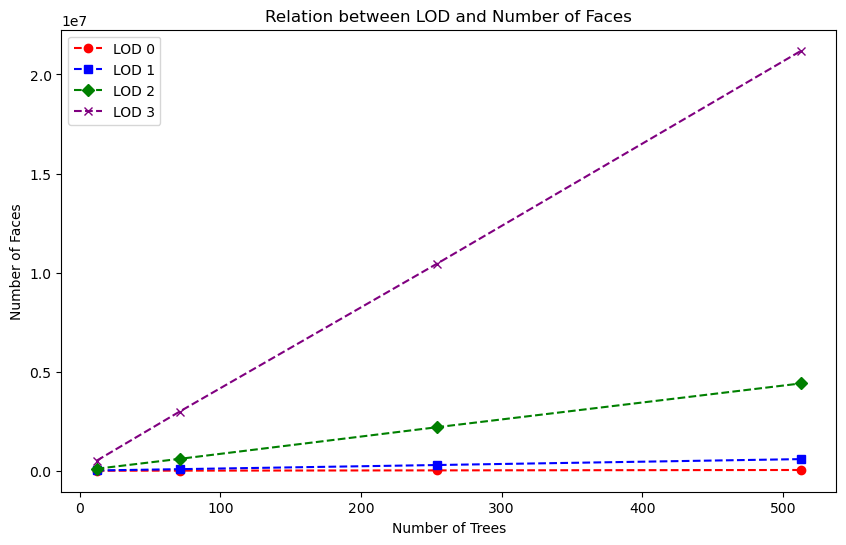
|
As we can see the number of faces for the LOD 3 level is significantly higher than for the other levels. This level might be too detailed for the use case of the program.
2. Execution time
We also measured the execution time of our program for each bounding box. The following figures shows the relationship between the number of trees and the execution time of our program for each LOD level with and withoud autorefine option.
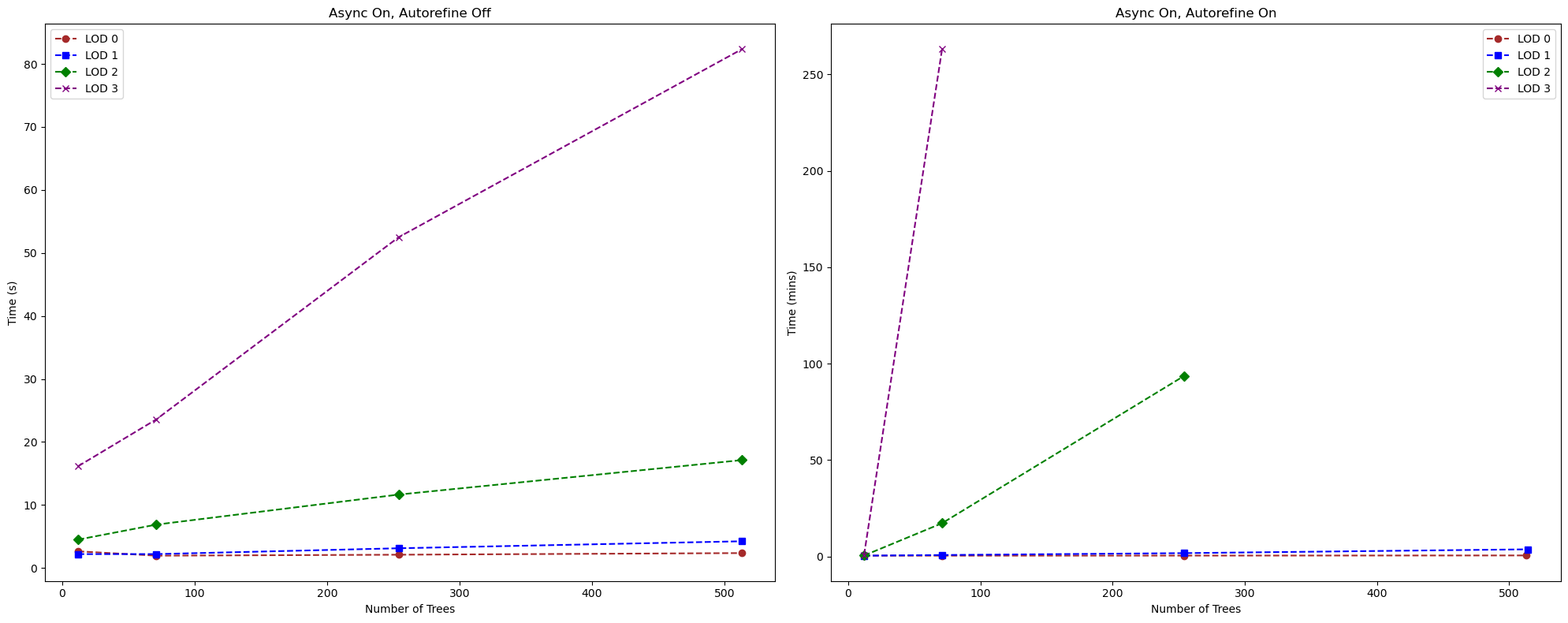
As we can see, the execution time seems to increase linearly with the number of trees. The autorefine option have a significant impact on the execution time, especially for the LOD 3 level which takes more than 600 times longer to compute with the autorefine option.
3. Effect of async
Finally we measured the effect of the async option on the execution time of our program. The following figure shows the improvement in execution time when using the async option.
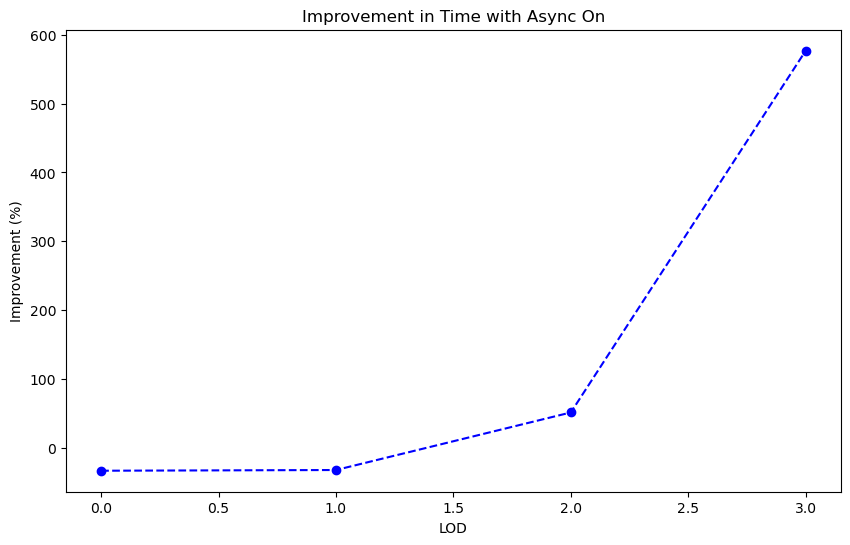
Contrairy to what we could expect, the thread parallelization is not an improvement in lower LOD levels. This might due to the overhead of creating and managing threads as well as the fact that the computation is not complex enough to benefit from parallelization since we have a small number of triangles to deal with. However, for the LOD 2 and 3 levels, the async option provides a significant improvement in execution time. More analysis is needed to understand the behavior of the program with the async option but collecting data on higher LOD levels is difficult due to the long execution time.